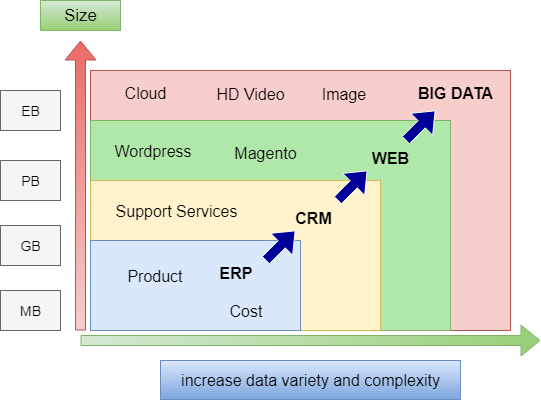
Big Data คือ ชุดของชุดข้อมูลที่มีขนาดใหญ่และซับซ้อนมาก เป็นเรื่องยากที่จะประมวลผลโดยใช้เทคโนโลยีการประมวลผลข้อมูลแบบเดิม
ตัวอย่างของ Big Data
- Facebook
- มีข้อมูลประมาณ 400 เทราไบต์ (TB)
- มีข้อมูลใหม่เข้ามาประมาณ 20 เทราไบต์ (TB) ต่อวัน
- New York Stock Exchange (NYSE) หรือตลาดหลักทรัพย์นิวยอร์ก
- สร้างข้อมูลทางการค้าขนาดประมาณ 1 เทราไบต์ (TB) ต่อวัน
- Internet Archive (การเก็บข้อมูลทางอินเตอร์เน็ต)
- จัดเก็บข้อมูลประมาณ 2 เพตาไบต์ (PB)
- มีอัตราการเพิ่มขึ้น 20 เทราไบต์ (TB) ต่อเดือน
- Skybox imaging (satellite images) หรือภาพถ่ายจากดาวเทียม
- จัดเก็บข้อมูลขนาด 1 เทราไบต์ต่อวัน
- com หรือธุรกิจตรวจ DNA
- จัดเก็บข้อมูลทั้งหมดประมาณ 2.5 เพตาไบต์ (PB)
Big Data Evolution
ความท้าทายในการประมวลผล (โดยใช้เทคโนโลยีแบบเดิม)
- Slow to process (ประมวลผลช้า)
- ใช้เวลา 11 วัน ในการอ่านข้อมูลประมาณ 100 เทราไบต์ โดยใช้คอมพิวเตอร์เพียงตัวเดียว
- Slow to move data (ย้ายข้อมูลช้า)
- การย้ายข้อมูลผ่านเครือข่ายช้า
- Can’t scale (ไม่สามารถปรับขนาดได้)
- เพิ่มประสิทธิภาพของการประมวลผล (หน่วยความจำ, ฮาร์ดแวร์ที่ทรงพลัง) ถูกจำกัดไว้
- Hard drive capacity is limited (หน่วยความจำมีพื้นที่จำกัด)
- หน่วยความจำตัวเดียวไม่สามารถรองรับขนาดข้อมูลขนาดใหญ่ได้
- Unreliable (ไม่น่าเชื่อถือ)
- ความล้มเหลวในคอมพิวเตอร์เป็นสิ่งที่หลีกเลี่ยงไม่ได้
คุณลักษณะของ Big Data
- ข้อมูลมีขนาดใหญ่มาก มีการกระจายตัวของโครงสร้างข้อมูลแบบ loosely
- ขนาดของข้อมูลมีหน่วยเป็น เพตาไบต์ (PB) / เอกซาไบต์ (EB)
- โครงสร้างที่มีความสัมพันธ์แบบไม่ซับซ้อนมากนัก
- จะใช้การประทับเวลาเข้ามาเกี่ยวข้องกับเหตุการณ์ต่างๆ
- ประกอบด้วยข้อมูลที่ไม่สมบูรณ์มากนัก
ความท้าทายในการจัดการข้อมูลขนาดใหญ่
- การย้ายข้อมูลจำนวนมากจากพื้นที่จัดเก็บเพื่อนำไปคำนวณที่ cluster (เพื่อลดค่าใช้จ่ายและได้ประสิทธิภาพการทำงานที่ชาญฉลาด)
- ย้ายข้อมูลไปยังคอมพิวเตอร์ที่มีประสิทธิภาพในการประมวลผลมากขึ้น
- การจัดการข้อมูลใหญ่ และความล้มเหลว
- เหตุการณ์ขัดข้องของเครื่องคอมพิวเตอร์และระบบเครือข่าย
- มีราคาแพงในการสร้างเครื่องคอมพิวเตอร์ที่มีประสิทธิภาพสูง และความน่าเชื่อถือในการใช้งานแอปพลิเคชันต่างๆ
- ความน่าถือในการจัดการระบบโดยใช้ framework
สิ่งที่ต้องพิจารณาในการวิเคราะห์ Big Data
- Volume (การจำกัดปริมาณ) – การจัดการข้อมูลขนาดใหญ่ในการทำธุรกิจ
- Velocity (ความเร็ว) – มีความเร็วในการจัดเก็บ วิเคราะห์ และดึงข้อมูลจำนวนมาก
- Variety (ความหลากหลาย) – สามารถประมวลผลข้อมูลได้จากหลายๆแหล่ง และข้อมูลสำคัญที่ไม่มีโครงสร้างข้อมูล
- Value (ราคา) – ถามคำถามที่ถูกต้องเพื่อสร้างมูลค่าสูงสุด
Examples of Public Data Sets
- S. Government – http://usgovxml.com/
- Amazon – http://aws.amazon.com/public-data-sets/
- Weather data from NCDC – http://www.ncdc.noaa.gov/data-access
- Million Song Dataset – http://labrosa.ee.columbia.edu/millionsong/
![]()
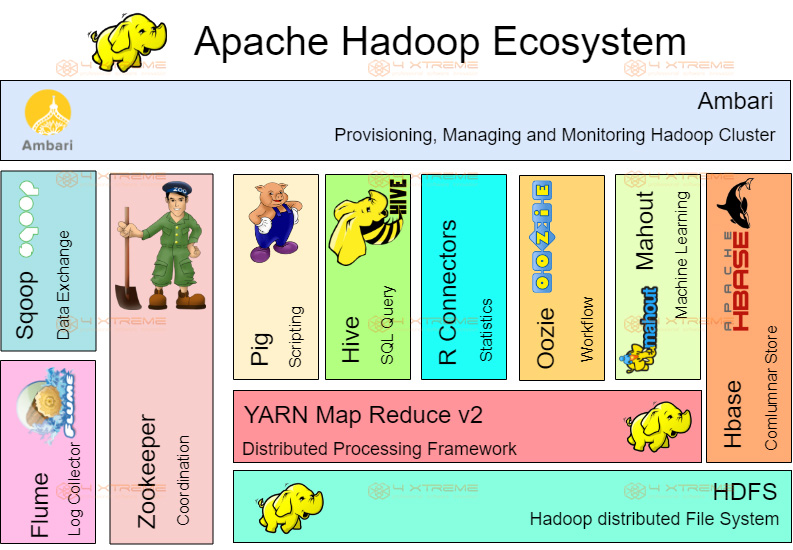
Hadoop คืออะไร
- Apache Hadoop เป็น framework ที่ช่วยในการกระจายการประมวลผลข้อมูลขนาดใหญ่ผ่าน cluster ที่มีความหลากหลาย โดยใช้รูปแบบการเขียนโปรแกรมแบบง่าย
- มีการออกแบบมาเพื่อเพิ่มขนาดจากโหนดเดียวเป็นโหนดหลายพันโหนด ซึ่งแต่ละที่ทำการคำนวณและเก็บข้อมูลการคำนวณนั้นไว้
ประวัติความเป็นมาของ Hadoop
- เริ่มต้นจากการเป็นโครงการย่อยของ Apache Nutch
- Nutch ใช้สำหรับจัดทำ indexing data และแสดงผลเพื่อค้นหา
- เปิดให้เป็น open source และส่งไปยัง Google
- เริ่มโดย Doug Cutting
- ในปี ค.ศ. 2004 ทาง Google ได้เผยแพร่เอกสาร Google File System (GFS) และ Map reduce
- Doug Cutting และทีมของ Nutch ได้ใช้ระบบ GFS และเพื่อ
- ในปี ค.ศ. 2006 Yahoo ได้ทำการจ้าง Doug Cutting มาทำงานใน Hadoop
- ในปี ค.ศ. 2008 Hadoop กลายเป็นโครงการ Apache Top Level http://hadoop.apache.org/
ทำไมต้อง Hadoop
- Scalable (สามารถปรับขนาดได้) – สามารถเพิ่มโหนดใหม่ลงในเครื่อง cluster ได้
- Economical (ประหยัด) – สามารถใช้ได้ในอุปกรณ์หลายแบบ
- Efficient (มีประสิทธิภาพ) – จะทำงานเฉพาะตำแหน่งที่มีข้อมูลอยู่
- Flexible (มีความยืดหยุ่น) – สามารถจัดการข้อมูลที่ไม่มีโครงสร้างให้น้อยลง
- Fault tolerant (แก้ไขข้อผิดพลาด) – สามารถค้นหาข้อผิดพลาดในโหนดต่างๆ และสามารถแก้ไขข้อผิดพลาดได้
- Simple (มีความง่าย) – ใช้รูปแบบการเขียนโปรแกรมแบบง่าย
- Evolving (พัฒนา) – มีระบบพัฒนาเป็นแบบ ecosysytem
หลักการออกแบบ Hadoop
- จัดเก็บและประมวลข้อมูลจำนวนมาก
- มีการจำกัด ประสิทธิภาพ พื้นที่จัดเก็บ และการประมวลผล
- แปลงรหัสคอมพิวเตอร์ไปเป็นข้อมูล
- การกู้คืน สามารถกู้คืนเมื่อเกิดความล้มเหลวในการสร้าง
- ถูกออกแบบมาเพื่อใช้กับฮาร์ดแวร์ที่มีความหลากหลาย
เมื่อไรที่ควรใช้หรือไม่ควรใช้ Hadoop
- Hadoop ดีสำหรับ
- Indexing data
- การวิเคราะห์เชิงตรรกะ
- การจัดการรูปภาพ
- การจัดเรียงข้อมูลขนาดใหญ่
- การทำเหมืองข้อมูล
- Hadoop ไม่ดีสำหรับ
- การประมวลผลแบบ real time
- การเข้าถึงข้อมูลแบบสุ่ม
- งานที่มีปริมาณมากและมีข้อมูลเพียงเล็กน้อย
- ข้อจำกัด บางประการของ Hadoop มีอยู่ใน Hadoop ecosystem
Comparing Hadoop with Other Technologies
|
Hadoop |
VS | RDBMS |
| ข้อมูลขนาดใหญ่ | ข้อมูลขนาดเล็ก | |
| โครงสร้างแบบหลวมๆ | โครงสร้างแบบรัดแน่น | |
| Schema on read | Schema on write | |
| ไม่มีความสัมพันธ์กัน | มีความสัมพันธ์กัน | |
| Analytics-oriented | Transaction-oriented | |
| Non-ACID | ACID | |
| Batch-oriented | Real-time query | |
| เขียนครั้งแรก ไม่มีการอัพเดตหรือลบ | มีการเขียนหรืออัพเดตบ่อย | |
| กระจายข้อมูล | ข้อมูลส่วนกลาง | |
| มีความยืดหยุ่นสูง |
ความยืดหยุ่นที่ถูกจำกัด |
Apache Hadoop System