
Hadoop Pig
![]()
What is and Why Apache Pig?
- Apache Pig is a platform for analyzing large data sets and is made of
- Pig Latin: a high-level, data flow, scripting language for expressing data analysis
- Pig runtime: มีโครงสร้างพื้นฐานสำหรับการประเมินผล script
- Pig script ที่เขียนด้วย Pig Latin จะถูกแปลงเป็นงาน MapReduce โดย Pig runtime
- Pig script มีการสร้างและการเรียกใช้งานได้ง่ายกว่า MapReduce code
- ถูกออกแบบมาเพื่อใช้ในการวิเคราะห์ข้อมูล โดยไม่จำเป็นต้องมีการช่วยเหลือจาก MapReduce Java developers
- Pig ใช้กันอย่างแพร่หลาย เป็นทางเลือกให้กับ MapReduce
- ใช้กันอย่างแพร่หลาย เช่น Yahoo, LinkedIn, Twitter, NetFlix etc.
| MapReduce | VS | Pig |
|---|---|---|
| Must be written in Java | Written in scripting language | |
| Must be done in “map” and “reduce” paradigm (mandates low-level thinking) | High-level abstraction (enables more natural thinking) | |
| Hard to do more useful yet advanced operations such as filtering, sorting, aggregation, joining, splitting | Easy to do filtering, sorting, aggregation, joining, splitting | |
| Provides several sophisticated data types (tuples, bags and maps) | ||
| ~20 times shorter than MapReduce code with only slightly slower than MapReduce |
| SQL | VS | Pig |
|---|---|---|
| Declarative language | Data flow language | |
| Complete result for each query the query could be complex | Data can be stored/dumped at any point in the pipeline |
Pig Use Cases
- Scaling Extract – Transform – Load (ETL) process on a large data set
- Pig is built on top of Hadoop, สามารถขยายเป็น server ขนาดใหญ่ได้ จึงสามารถประมวลชุดข้อมูลขนาดใหญ่ได้
- Analyzing data with unknown or inconsistent schema
- Pig can Load, Filter (clean), Join, Group,Sort, and Aggregate large amounts of data with unknown or inconsistent schema
Benefits of Pig Latin Language
- Ease of programming
- มีภาษา script ระดับสูง
- งานที่ความซับซ้อน ซึ่งมีการแปลงข้อมูลหลายแบบที่เกี่ยวข้องกัน (joining, grouping, splitting, etc) สามารถแสดงได้อย่างง่ายดาย
- Optimized implementation
- Pig runtime is highly optimized
- Extensibility
- ผู้ใช้สามารถสร้างฟังก์ชันของตนเอง (เรียกว่า User Defined Functions) เพื่อทำการประมวลผลพิเศษ
- ผู้ใช้สามารถเขียนคำศัพท์ script ของตนเองได้
Executing Pig
Pig Execution Modes: Shell and Script
- Shell (Grunt shell) execution mode
- Interactive shell for executing Pig commands
- Started when script file is not provided when “pig” command is run
- Support file system commands within the shell such as “cat” or “ls”
- Can execute scripts within the shell via “run” or “exec” commands
- Useful for development
- Script execution mode
- Execute “pig” command with a script file
Pig Execution Modes: Local vs MapReduce
- Local mode
- Executes in a single JVM
- Accesses files on local file system
- Used for development
- pig -x local (Interactive shell called Grunt)
- pig -x local <script-file> (Script)
- MapReduce mode (Hadoop mode)
- Executes on Hadoop cluster and HDFS
- pig or pig -x mapreduce (Interactive shell called Grunt)
- pig <script-file> or pig -x mapreduce <script-file> (Script)
Ways to execute Pig Script
- Running Pig at the command line
- Using locally installed Hue (Hadoop Web UI)
- Using net accessible Hue (Hadoop Web UI) through Cloudera Live
- ใช้ตัวเลือกนี้หากไม่ได้ติดตั้ง Hadoop ไว้ในเครื่อง
Example: word-count.pig
- In the hands-on lab, we are going to do the following
- Run each Pig statement in Grunt shell and dump the result
- Run it as a script at the command-line
- Run it via Hue Web UI

Pig Latin Concepts
Pig Lation Data Types
- Field
- Piece of data
- Tuple
- An ordered set of fields
- Represented with parentheses (..) Example: (11, john, us)
- เทียบได้กับ “rows” ใน RDBMS
- Bag
- Collection of tuples
- Represented with braces {..}
- Example: { (11, john, us), (33, shin) }
- เทียบกับ “ตาราง” ใน RDBMS – Bags ไม่จำเป็นต้องให้ tuples ทั้งหมดมีหมายเลขเดียวกันหรือข้อมูลประเภทเดียวกัน
- Relation
- Is a bag (more specifically, an outer bag)
Referencing Relations
- ความสัมพันธ์ถูกเรียกตามชื่อ (หรือนามแฝง)
- Names are assigned by you as part of the Pig Latin statement
- In the example below, the name (alias) of the relation is A.

Schema Data Types supported in Pig
- Simple type
- int, long, float, double
- Array
- chararray: Character array (string) in UTF-8
- bytearray: Byte array (blob)
- Complex data types
- tuple: an ordered set of fields (19,2)
- bag: a collection of tuples {(19,2), (18,1)}
- map: a set of key value pairs [open#apache]
Referencing Fields
- Fields are referred to by positional notation or by name
- Positional notation is indicated with the dollar sign ($) and begins with zero (0); for example, $0, $1, $2

Referencing Complex Data Type Fields
- The fields in a tuple can be any data type, including the complex data types: bags, tuples, and maps

Outer Bag and Inner Bag

Case Sensitivity
- The names (aliases) of relations A, B, and C are case sensitive
- The names (aliases) of fields f1, f2, and f3 are case sensitive
- Function names PigStorage and COUNT are case sensitive
- Keywords LOAD, USING, AS, GROUP, BY, FOREACH, GENERATE, and DUMP are case insensitive. They can also be written as load, using, as, group, by, etc.

Pig Latin Script: Operators & Functions
Pig Latin Operators
- relational operators
- LOAD,FOREACH, FILTER, JOIN, GROUP, ORDER, UNION, SPLIT, STORE, DUMP, LIMIT, DISTINCT
- Arithmetic operators
- +, -, *,/ ,% ,etc.
- Diagnostic operators
- DESCRIBE, EXPLAIN, ILLUSTRATE, DUMP
Pig Latin Built-in Function
- Eval functions
- AVG, COUNT, MAX, MIN, SIZE, SUM, TOKENIZE, etc
- Load/Store functions
- PigStorage, BinStorage, HBaseStorage, etc
- Math functions
- ABS, RANDOM, SORT, CEIL, FLOOR, etc
- String functions
- LOWER, UPPER, SUBSTRING, REPLACE, ENDSWITH, etc
- Datetime functions
- CurrentTime, DaysBetween, etc
Pig Latin Script Structure
- A Pig script is made of a sequence of Pig statements
- A Pig statement is constructed using
- Relational operator
- Arithmetic operator
- Functions
- The result of Pig statement execution is captured into a relation

Pig Latin Script: Flow
Typical Pig Latin Script Flow
Step #1: Load data from the file system
- LOAD
Step #2: Perform a series of “transformation” to the data
- FILTER, FOREACH, GROUP, JOIN, UNION, SPLIT, SORT
Step #3: Execute and than display or save result
- DUMP (to display result) or STORE (to save the result into HDFS or HBase)
- DUMP or STORE triggers the execution
Step #1: Load Data using LOAD statement
LOAD ‘data’ [USING function] [AS schema];
- ‘data’ : The name of the file or directory, in single quotes
- [USING function]: specifies the load function to use
- PigStorage is the default function
- PigStorage( [field_delimiter] , [‘options’] ): The default field delimiter is tab (‘\t’), but can be customized with regular expression
- [AS schema]: Schemas enable you to assign names to fields and declare types for fields
- You can use the DESCRIBE operator to view the schema

Step #2: Perform Transformation to Data
- Use FILTER operator to work with tuples (rows of data)
- To filter out tuples based on condition
- Use FOREACH operator to work with columns of data
- To select columns
- With a single relation
- Use GROUP operator to group data in a single relation
- With multiple relations (we will cover these in PIG Part 2 presentation)
- Use COGROUP, inner JOIN, and outer JOIN operators to group or join data in two or more relations
- Use UNION operator to merge the contents of two or more relations
- Use SPLIT operator to partition the contents of a relation into multiple relations
Pig Latin Relational Operators
Filter Operator
- Use the FILTER operator to work with tuples or rows of data (if you want to work with columns of data, use the FOREACH…GENERATE operation).
- FILTER is commonly used to select the tuples that you want; or, conversely, to filter out (remove) the tuples you don’t want

FOREACH … GENERATE Operator

FLATTEN Operator
- Flatten un-nests tuples as well as bags

TOKENIZE Function
- Splits a string into tokens and outputs as a bag of words

GROUP Operator

ORDER alias BY Operator

Step #3: DUMP or STORE
- No action is taken until DUMP or STORE commands are executed
- Pig will parse, validate, and analyze the statements but not execute them until DUMP or STORE commands are executed
- DUMP is for displaying the result to the screen
- Mostly used during development time
- STORE is for saving the results into HDFS or HBase
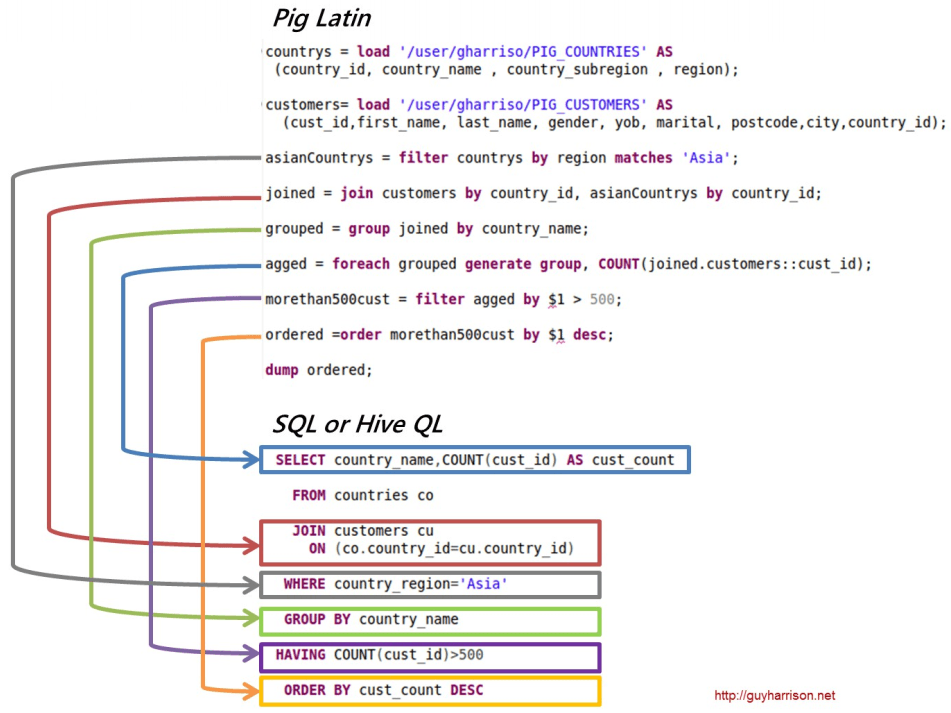
Pig Latin Diagnostic Operators
DESCRIBE, ILLUSTRATE, EXPLAIN
- DESCRIBE displays the structure of the schema
- ILLUSTRATE shows how Pig engine transforms the data
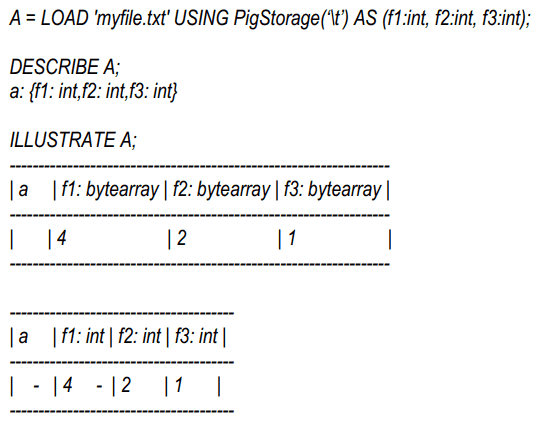
- EXPLAIN produces various reports
- Logical plan, Physical plan, MapReduce plan
