
What is and Why HBase?
HBase is a type of NoSQL database
- NoSQL is a general term meaning that the database isn’t an RDBMS which supports SQL as its primary access language, but there are many types of NoSQL databases
- BerkeleyDB is an example of a local NoSQL database, whereas HBase is very much a distributed NoSQL database
- Technically speaking HBase เป็น Data Store มากกว่าเป็น Data Base because it lacks many of the features you find in an RDBMS, such as typed columns, secondary indexes, triggers, and advanced query languages, etc.
![]()
HBase Features
- มีความสอดคล้องกัน (แต่ไม่ใช่ “สอดคล้องกันที่สุด”) การอ่าน/เขียน
- ทำให้เหมาะสำหรับงานต่างๆ เช่น high-speed counter aggregation
- Automatic sharding
- HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows
- Automatic RegionServer failover
- Hadoop/HDFS Integration
- HBase supports HDFS out of the box as its distributed file system
- MapReduce
- HBase สนับสนุนการประมวลผลแบบ parallel ผ่าน MapReduce
- Java Client API
- HBase รองรับ Java API สำหรับการเข้าถึงการเขียนโปรแกรม
- Thrift/REST API
- HBase สนับสนุน Thrift และ REST สำหรับ front-end ที่ไม่ใช่ Java
- Block Cache and Bloom Filters
- HBase supports a Block Cache and Bloom Filters for high volume query optimization (Bloom filters provide a lightweight in-memory structure to reduce the number of disk reads for a given Get operation)
- Operational Management
- HBase provides build-in web-pages for operational insight as well as JMX metrics
When to use HBase?
- Use it when you have large data set
- ข้อมูลที่มีขนาดร้อยล้านหรือพันล้านแถวและคอลัมน์
- Use it when you can live without all the extra features that an RDBMS provides (e.g., typed columns, secondary indexes, transactions, advanced query languages, etc.)
- Consider moving from an RDBMS to HBase as a complete redesign as opposed to a port.
- Use it when you have enough hardware (ใช้เมื่อมีฮาร์ดแวร์เพียงพอ)
- You need more nodes for HBase Master, Zookeeper
- HDFS doesn’t do well with anything less than 5 DataNodes (due to things such as HDFS block replication which has a default of 3), plus a NameNode.
HDFS vs HBase
- HDFS เป็นระบบไฟล์แบบกระจายซึ่งเหมาะสำหรับการจัดเก็บไฟล์ขนาดใหญ่
- High latency and batch oriented
- Does not provide fast individual record lookups in files
- HBase
- Built on top of HDFS
- มีการค้นหา record ที่รวดเร็ว (และการอัปเดต) สำหรับข้อมูลขนาดใหญ่ (low latency access)
- HBase internally puts your data in indexed “StoreFiles” that exist on HDFS for high-speed lookups
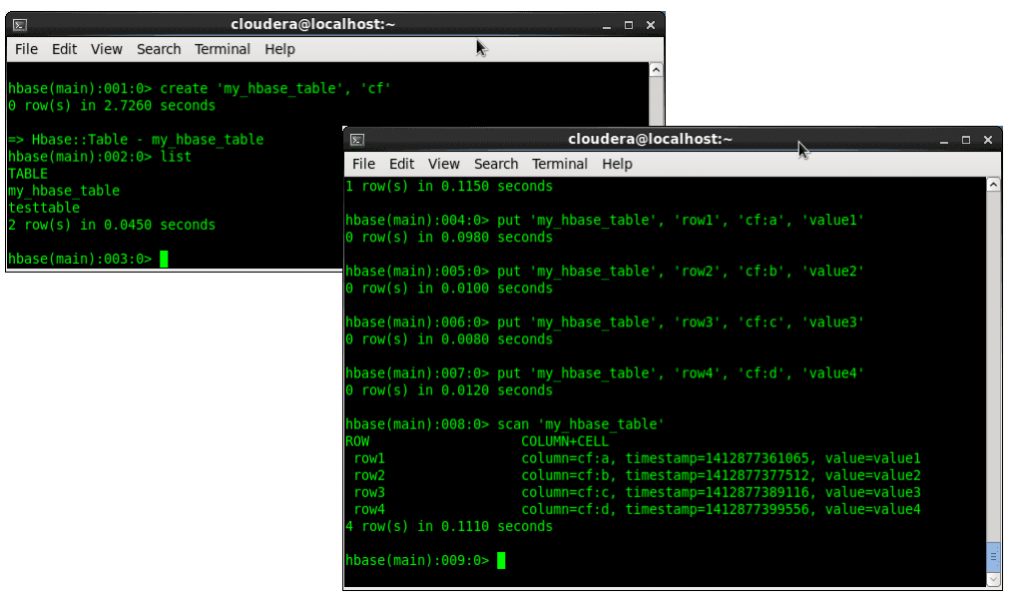
HBase Shell
You can create HBase table, add rows, get, update, and delete a row
HBase Architecture: Master/Slaves
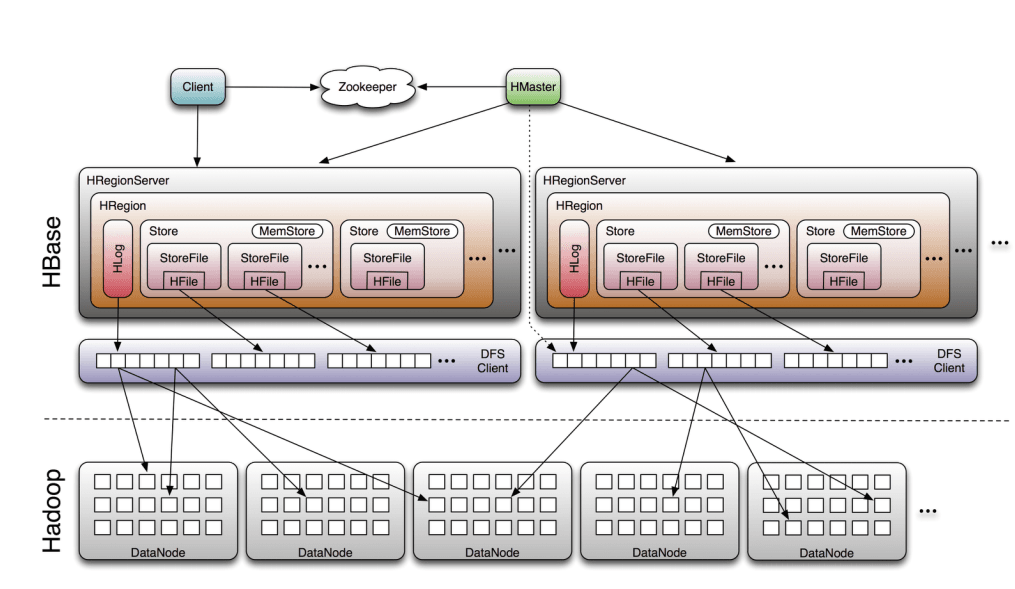
- Table is made of regions
- Region คือช่วงของแถวที่เก็บไว้ด้วยกัน
- Dynamically split as they become too big and merged if too small
- Region Server serves one or more regions
- A region is served by only 1 Region server
- Master Server is responsible for managing a cluster of Region servers
- HBase เก็บข้อมูลไว้ใน HDFS
- อาศัยระบบไฟล์แบบกระจายของ HDFS
- HBase ใช้ Zookeeper สำหรับการประสานงานแบบกระจาย
- ZooKeeper เป็นเครื่องมือที่ใช้ทั่วไปสำหรับการประสานงานแบบกระจาย
Read and Write
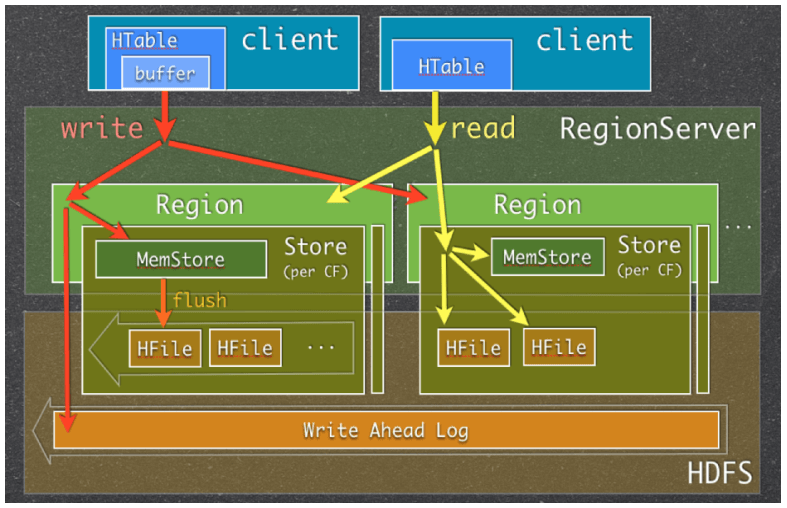
Role of MemStore
- Store data ordered by row key
- HDFS ได้รับการออกแบบมาสำหรับการอ่าน / เขียนตามลำดับ ซึ่งไม่อนุญาตให้มีการแก้ไขไฟล์ HBase นั้นไม่สามารถเขียนข้อมูลลงในดิสก์ได้อย่างมีประสิทธิภาพเมื่อข้อมูลที่รับมายังไม่ได้เรียงลำดับ ซึ่งไม่เหมาะสำหรับการดึงข้อมูลมาใช้ในอนาคต
- เพื่อแก้ปัญหานี้ HBase ได้ buffer ข้อมูลสุดท้ายที่ได้รับใน memory มาเรียงลำดับก่อนที่จะเขียนลง HDFS
- ทำหน้าที่เป็นแคชในหน่วยความจำ ซึ่งช่วยเก็บข้อมูลที่เพิ่มเมื่อเร็วๆนี้
- ซึ่งมีประโยชน์ในหลายกรณีเมื่อมีการเข้าถึงข้อมูลที่เขียนขึ้นบ่อยกว่าข้อมูลที่เก่ากว่า
- Data in MemStore gets flushed when flush threshold is met
- Set by hbase.hregion.memstore.flush.size
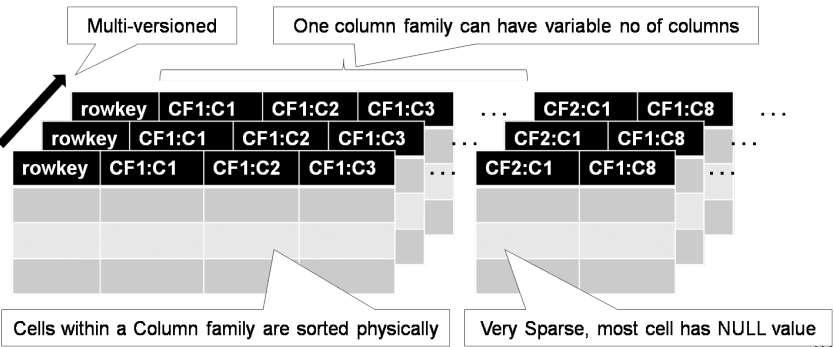
HBase Data Model
- Row: is made of several column families
- Column family: is made of several columns
- Column: represents a field
Row-Oriented vs Column-Oriented
- RDBMS เป็นแบบ Row-Oriented
- HBase เป็นแบบ Column-Oriented.
| RDBMS (Row-Oriented) | VS | HBase (Column-Oriented) |
|---|---|---|
| Small number of columns and small number of rows | Large number of columns (tens of millions) | |
| Query model is reading a set of rows (OLTP) | Query model is aggregation against column values (OLAP) | |
| High compression possible due to duplicate values in columns |
How to Store Bulk Data into HBase
- Pig
- Hive
- MapReduce
- Flume
Store Data into HBase Table via PIG
Step 1: Create HBase table first

Step 2: Store data into the HBase Table using HBaseStorage using PIG statement
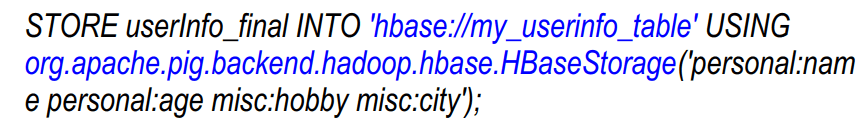
Accessing Data in HBase Table using REST/Thrift Interface
REST/Thrift Support
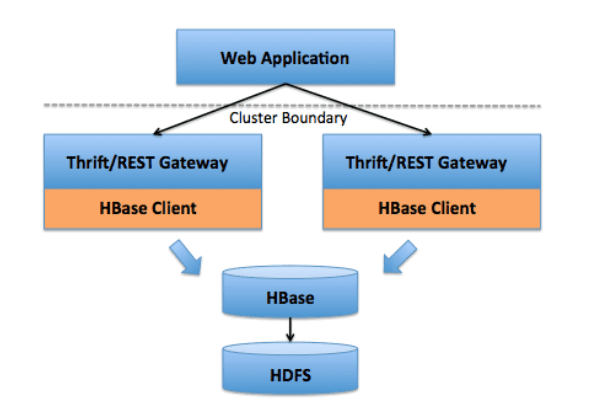
- Allows non-Java access to HBase
- REST interface
- Supports wider array of languages, programs, and client types that can access the interface than THRIFT interface
- Thrift interface
- มีขนาดที่เล็กและเร็วกว่า REST interface
- Allows non-Java languages to access HBase over Thrift by connecting to a Thrift server that interfaces with the Java client