
What is and Why Hive?
What is Hive?
- Provides data warehousing solution built on top of Hadoop
- ช่วยอำนวยความสะดวกในการค้นหาและจัดการชุดข้อมูลขนาดใหญ่ที่อยู่ใน Hadoop Storage (HDFS หรือ HBase)
- มาพร้อมกับภาษา SQL ทีเรียกว่า HiveQL
- SQL has huge developer base
- นำความสามารถของ Hadoop มาใข้ (querying, analyzing, and summarizing large amounts of data)
- Allows you to project structure to any data formats
- Can handle non-structured data
- Open source Apache project
- Started at Facebook
![]()
Hive is NOT designed for
- Hive is not for real-time queries
- Hive is still a batch operation: Hadoop jobs incur substantial overheads in job submission and scheduling – not suitable for real-time queries.
- ผลที่ตามมา – ความล่าช้าในการค้นหาของ Hive ซึ่งโดยทั่วไปมีสูงมากแม้ว่าข้อมูลนั้นจะมีขนาดเพียงหลักร้อยเมกะไบต์
- Hive ได้รับการออกแบบมาเพื่อความสามารถในการปรับขนาดและใช้งานได้ง่าย
- Hive is not for Online Transaction Processing (which requires real time and frequent write operations)
- Hive is more for Online Transaction Analysis (in Batch mode), which requires mostly read operations
- Hive does not support UPDATE/DELETE/INSERT a single row
Example Hive Applications
- Log processing
- Text mining
- Document indexing
- Customer-facing business intelligence
- Example: Google Analytics
- Predictive modeling
- Hypothesis testing
| Hive | VS | RDMS |
|---|---|---|
| Similarities | Similarities | |
| – HiveQL (SQL-like language) – Similar data model-database, table, view |
– SQL – Similar data model-database, table, view |
|
| Differences | Differences | |
| – Designed for OLAP – Batch oriented and high latency operations – Schema on Read |
– Design for OLTP – Real-time and low latency operations – Schema on Write |
| Hive | VS | PIG |
|---|---|---|
| Similarities | Similarities | |
| – Batch oriented – HiveQL gets translated into MapReduce jobs – Targeted for non-Java developers (SQL developers) |
– Batch oriented – PIG statement gets translated into MapReduce jobs – Targeted for non-Java developers |
|
| Differences | Differences | |
| – HiveQL (like SQL) is a declarative language with a single result set | – PIG Latin is procedural data flow language with input and out for each step |
Hive Architecture
Hive Internals
- Hive แปลคำสั่ง HiveQL เป็นชุดงานของ MapReduce ซึ่งจะดำเนินการนี้อยู่ใน Hadoop Cluster
- Abstracted notions of traditional RDBMS are provided over Hadoop data sets through “metadata” store
- Database – namespace containing a set of tables
- Tables
- Schemas
- Indexing
- View
- Hive specific data models are also supported
- Partitions
- Buckets
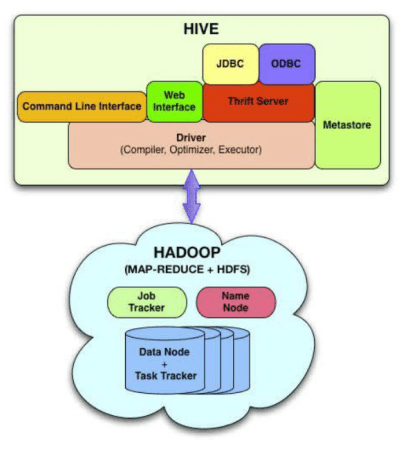
- Hive Interface options
- Command Line Interface (CLI)
- Web interface
- Thrift Server – Any JDBC an ODBC client apps can access Hive
- The “metadata” store is maintained internally via embedded Derby database (MySQL and other RDBMS are also supported)
- Table definitions
- Mapping to HDFS
HiveQL
- Types of HiveQL operations
- DDL operations
- DML operations
- SQL operations
- How to execute HiveQL
- Use Hive shell – just type “hive”
- Run Hive script file – type “hive –f <script-file>”
HiveQL – DDL operations
- Create a table

- Show tables
![]()
- Describe a table
![]()
- Drop a table
![]()
HiveQL – DML operations
- Loading flat files into Hive

- No verification of incoming data
- If the loaded data is not compliant with the schema specified forthe table, it will be set to NULL
HiveQL – SQL operations

HiveQL – Built-in Functions
- HiveQL comes with a bunch of built-in functions
- Hive -> SHOW FUNCTIONS ;
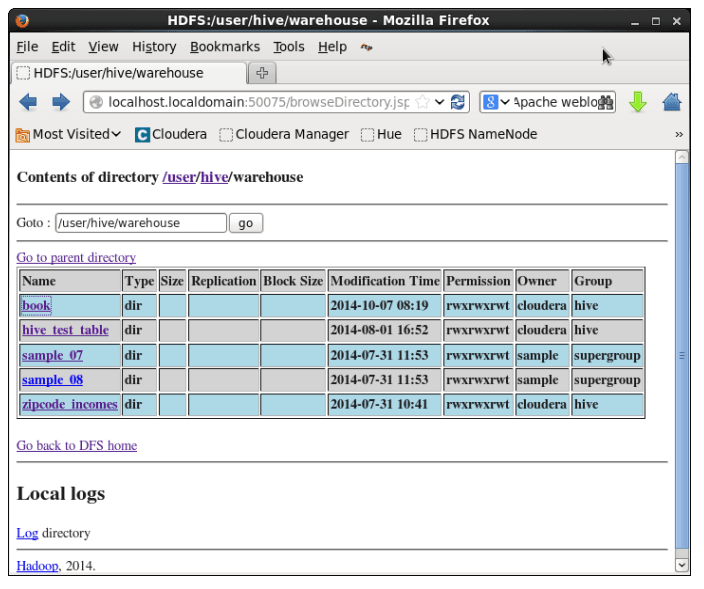
Physical Layout
- Hive warehouse directory in HDFS
- /user/hive/warehouse (default) – the default can be changed via hive.metastore.warehouse.dir
- Hive Table is represented as a directory under Hive warehouse directory
- /user/hive/warehouse/students directory – represents “students” Hive table
- /user/hive/warehouse/book directory – represents “book” Hive table
- Actual data is stored in flat files under the directory
Example: Physical Layout
- In the example below, there are 5 directories representing 5 tables
Loading Data into Hive Tables
Multiple Schemes of Loading Data
#1: Use Hive LOAD DATA command (Most common: our focus here)
- To load data from flat files
- Data files can be loaded from Local or HDFS (default)
- Data files can be loaded Internal (default) vs EXTERNAL
#2: Manually copying data files into the “/user/hive/warehouse/<tabledirectory>” Hive directory
- Hive automatically recognize them
#3: Use Hive INSERT command
- To load data from another HIVE table using SELECT (It is not for inserting a new record)
#4: Use Apache Sqoop to move RDMBS data to Hadoop
#5: Use Apache Flume to move large data sets to Hadoop
Loading data from Local vs HDFS
- Load data from local file system

- Load data from HDFS (default)

Loading data Internal vs EXTERNAL
- Load data Internally
- Data is moved to Hive storage (/user/hive/warehouse)
- การลบตาราง Hive ข้อมูลก็จะถูกลบด้วย
- Load data with EXTERNAL … LOCATION
- ใช้ข้อมูลที่อยู่ใน HDFS
- Hive just has pointers to the existing data in HDFS when a table gets created
- ลบตาราง Hive ข้อมูลใน HDFS จะไม่ถูกลบ
- Load data Internal

- Load data EXTERNAL (done at CREATE time, no LOAD required)

Load Data from Existing Table using INSERT … SELECT
- Use it when you want to load data from existing table or tables

Hive Partitions
What is and Why Partitions?
- ข้อมูลภายในตารางถูกแบ่งออกเป็นหลาย partitions
- เพื่อเพิ่มประสิทธิภาพการทำงานของการค้นหาข้อมูล
- Each partition corresponds to a particular value(s) of partition column(s) and is stored as a sub-directory within the table’s directory on HDFS
- When the table is queried, where applicable, only the required partitions of the table are queried, thereby reducing the I/O required by the query
- For example, you might want to partition weather data base on year – when query operation is done per year, only that partition need to be accessed
Partitioning Data Mechanism
- One or more partition columns may be specified
- Creates a sub-directory for each value of the partition column
- Queries with the partition columns in WHERE clause will scan through only a subset of the data
Creating Partitions
- Specify the partition column

Load data into Partitions
- Each partition is loaded with data specific for the partition column

Querying Partitions
- By specifying the where condition with the partition, only that specific partition will be queried

Hive Joins
JOIN
- Hive supports
- Inner Join (default)
- Outer Join – Left Outer, Right Outer, Full Outer
- การ JOIN สามารถทำได้ในสองรูปแบบ
- Using SELECT … INNER JOIN.., SELECT… LEFT OUTER JOIN, etc

- Create a joined table from
- Using SELECT … INNER JOIN.., SELECT… LEFT OUTER JOIN, etc

What is and Why Buckets?
- เป็นกลไกในการสืบค้นและตรวจสอบจากการสุ่มข้อมูลตัวอย่าง
- Breaks data into a set of buckets based on a hash function of a “bucket column” and allows execution of queries on a subset of random data
- Bucketing must be configured
- hive> hive.enforce.bucketing = true;