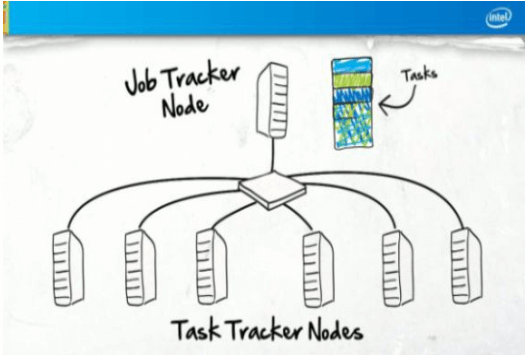
Hadoop MapReduce Architecture
- Job submitter (client) : ส่งงานไปหา job tracker
- One Job Tracker Node : ส่ง task ที่มีไปยัง task trackers และเพื่อให้เป็นการทำงานร่วมกัน
- Multiple Task Tracker nodes : ประมวลงานที่ได้รับมา
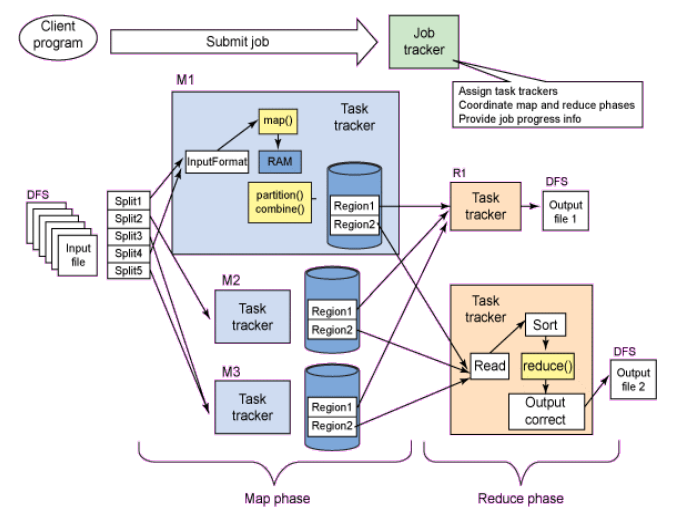
Job Execution Flow
- Job submitter (client) submits a job to Job Tracker
- Job Tracker creates execution plan
- Job Tracker sends tasks to Task Trackers
- Task Trackers performs tasks and also report progress to Job Tracker via heartbeats
- Job Tracker manages “map” and “reduce” phases
- Job tracker updates states
MapReduce Architecture
Basic Concept of MapReduce
- MapReduce is a programming model ถูกออกแบบมาเพื่อการประมวลที่มีข้อมูลขนาดใหญ่ในแบบ parallel โดยการแบ่งงานออกเป็นชุดๆ
- MapReduce programs are written in a particular style influenced by functional programming constructs, specifically idioms for processing lists of data
MapReduce uses Functional Programming
- การคำนวณปริมาณข้อมูลจำนวนมากแบบ parallel ต้องการมีการแบ่งปริมาณงานออกเป็นส่วนๆ เพื่อให้เครื่องอื่นช่วยทำงาน
- Non-functional programming model, where components were allowed to share data arbitrarily, will not scale to large clusters (hundreds or thousands of nodes)
- ค่าใช้จ่ายที่จำเป็นในการเชื่อมต่อ ก็เพื่อเก็บข้อมูลไว้ในโหนด โดยที่โหนดต่างๆนั้นจะต้องเชื่อมต่อกันอยู่ตลอดเวลา
- MapReduce uses functional programming ซึ่งองค์ประกอบของข้อมูลทั้งหมดใน MapReduce นั้นไม่สามารถอัพเดทหรือเปลี่ยนแปลงได้
- If, in a mapping task, you change an input (key, value) pair, it does not get reflected back in the input files; communication occurs only by generating new output (key, value) pairs, which are then forwarded by the system into the next phase of execution
List Processing: Map and Reduce
- Conceptually, a MapReduce program performs the transformation
- “lists of input data elements” -> “lists of output data elements”
- A MapReduce program will do this twice, using two different list processing idioms in two phases
- Using “map” idiom in “mapping” phase
- Using “reducing” idiom in “reducing” phase
Mapping Phase
- The first phase of a MapReduce program is called “Mapping” องค์ประกอบข้อมูลจะถูกจัดเตรียมไว้ให้กับฟังก์ชันที่เรียกว่า “Mapper” ซึ่งจะแปลงแต่ละองค์ประกอบให้เป็น ข้อมูลออก – เรียกว่า “การแมป”
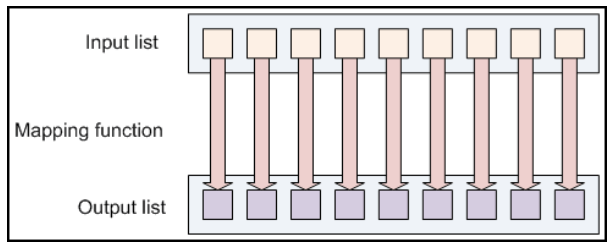
Mapping Lists Example
- A mapping function toUpper(str) which returns an uppercase version of its input string
- สามารถใช้ function ผ่าน map เพื่อให้ “a list if strings” เป็น “a list of uppercase string”
- Note : string ที่ได้มา ไม่ได้ถูกแก้ที่นี่แต่จะส่ง string ใหม่กลับไป ซึ่งเป็นผลลัพธ์ที่ได้จากการทำงาน
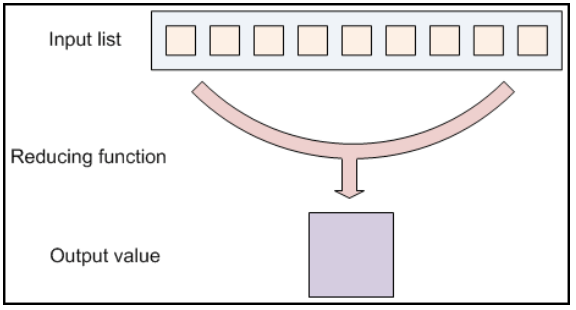
Reducing Phase
- Reducing lets you aggregate values together
- A reducer function receives an iterator of input values from an input list. จากนั้นจะรวมค่าที่ได้รับมาเหล่านั้นเข้าด้วยกัน และส่งคืนผลลัพธ์นั้นเป็นค่าเดียว
Reduce lists Examples
- Reducing มักถูกใช้เพื่อสร้างข้อมูลสรุป โดยทำให้ข้อมูลจำนวนมากกลายเป็นข้อมูลสรุปที่มีขนาดเล็กลง
- เช่น การบวก + สามารถใช้ reduce function ในการหาคำตอบจากการบวกเลขที่ได้รับจาก input หลายตัว
Hadoop MapReduce Programming
Hadoop MapReduce Framework
- The Hadoop MapReduce framework takes these concepts and uses them to process large volumes of data
- A MapReduce program has two components:
- Mapper: one that implements the mapper
- Reducer: one that implements the reducer
- Bother Mapper and Reducer takes input data and then generates output data
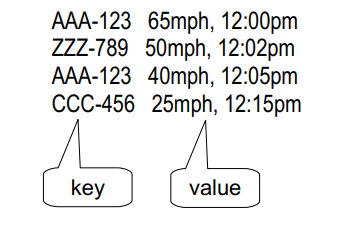
Keys and Values
- In Hadoop MapReduce, data element (in input and output) is always in key/value pair
- Every value has a key associated with it
- For example, a log of time-coded speedometer readings from multiple cars could be keyed by license-plate number; it would look like:
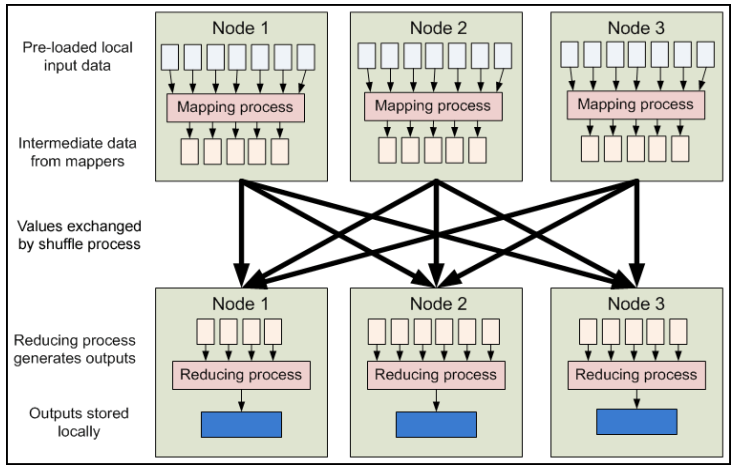
 MapReduce data flow
MapReduce data flow
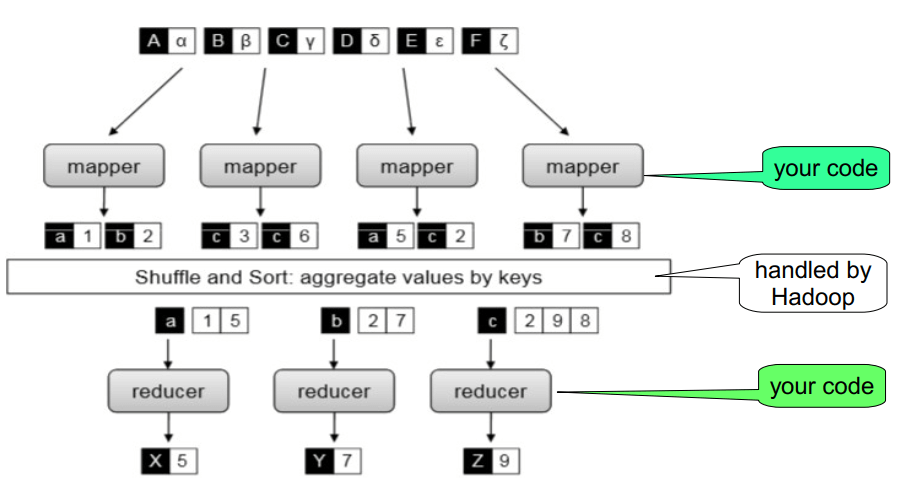
Hadoop MapReduce Framework
- Takes care of distributed processing and coordination
- Scheduling
- Jobs are broken down into tasks, which are then scheduled
- Task localization with data
- Hadoop framework sends the tasks (code) to nodes that host segment of data
- Error handling
- Tasks are automatically retried on other machines when errors occur
- Data synchronization
- Shuffles and sorts data
- Moves data between nodes
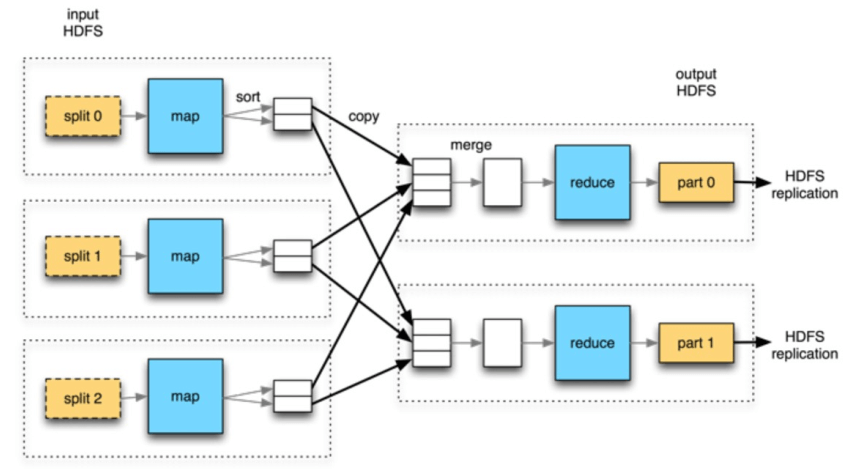
MapReduce Data Flow